Emulazione
Il concetto di emulazione, ossia «la possibilità di esecuzione, tramite software appositi, di programmi previsti per uno specifico tipo di elaboratore su un altro elaboratore con caratteristiche diverse» (secondo la definizione dal dizionario Sabatini-Coletti), è ormai di comune notorietà, grazie principalmente alla diffusione per i sistemi odierni, fissi e mobili, di svariati emulatori di vecchi computer e console di videogames. Tuttavia, appena si entra nel merito della discussione sull’emulazione, sia generica che specifica su una data macchina, vengono scritte e dette molte inesattezze, anche da parte di chi invece dovrebbe “informare” sul tema (a cui è sempre lecito chiedere il minimo sindacale di deontologia, invece molto spesso trascurato) e che si traducono anche in sonore castronerie. Quest’articolo nasce appunto con l’intento di fornire risposte esaustive e digeribili da chiunque, anche da chi è completamente a digiuno di informatica e di programmazione, sull’emulazione in generale. La prima domanda è la più ovvia e al tempo stesso la più importante.
1. Cos’è effettivamente un emulatore?
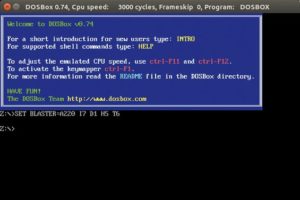
La definizione da dizionario riportata sopra è ovviamente corretta, ma occorre fare qualche precisazione: un emulatore è un software che permette l’esecuzione di software creato per un determinato sistema, o famiglia di essi, su un altro sistema o famiglia per cui quel software non era pensato. Un emulatore nasce con l’intenzione di replicare quanto più fedelmente possibile il funzionamento (“emulare”, appunto) dell’hardware e del firmware di una specifica macchina, con lo scopo di poter eseguire un software scritto nei linguaggi comprensibili dalla macchina emulata e non da quella emulante. Il concetto chiave è questo: un emulatore funziona solo e soltanto con il software del sistema emulato, recuperato secondo metodi che verranno descritti in seguito. Un esempio noto ai più: DOSBox, l’emulatore per vari sistemi odierni di un PC IBM compatibile con sistema operativo DOS, capace di emulare perfettamente varie configurazioni hardware (una prassi dell’epoca), con diverse schede video, audio e di rete, nonché driver per periferiche come mouse e joystick.
Questa definizione permette di definire anche la differenza sostanziale che intercorre tra emulazione e altri metodi per l’esecuzione di software per macchine diverse, come ad esempio il porting, ovvero la riscrittura totale o parziale del codice sorgente di un programma affinché possa essere eseguito nativamente su un’altra macchina, senza l’utilizzo di altro software di compatibilità. Va detto che esistono anche delle soluzioni spurie, come ad esempio quella di Microsoft per poter eseguire su Xbox One giochi fisici per Xbox 360: alcune funzionalità, come i salvataggi su disco, vengono effettivamente emulate, ma il software eseguito è una versione del gioco ricompilata ad hoc per Xbox One da scaricare e installare, ovviamente diversa da quella contenuta nel Blu-ray. Un’altra distinzione va fatta anche tra emulazione e virtualizzazione: la virtualizzazione è quella procedura di astrazione, effettuata tramite opportuno software, di alcune componenti hardware fisiche affinché si possano installare sistemi operativi oltre quello del sistema nativo ed eseguire programmi per quest’ultimi. Quindi, banalizzando al massimo, un software di virtualizzazione “prende in prestito” hardware e periferiche fisicamente presenti nel sistema ospite, mentre un emulatore ne replica il funzionamento esclusivamente via software.
[restrict userlevel=”subscriber”]
2. Perché si usano gli emulatori?
Lo sviluppo e l’utilizzo degli emulatori è una delle strategie utilizzate per la cosiddetta “preservazione digitale”, ossia la conservazione delle informazioni nel tempo. Così come i supporti materiali con cui l’uomo ha potuto conservare e trasmettere il suo sapere nel corso dei secoli (pergamena, carta, etc.) sono suscettibili al deterioramento, in maniera analoga le tecnologie per la memorizzazione e l’accesso a informazioni digitali diventano obsolete nel tempo, per giunta molto più velocemente rispetto al supporto materiale. Ad esempio, mentre la carta di un libro ci mette oltre un secolo prima di iniziare a deteriorarsi, un floppy disk da 3,5” è già obsoleto da oltre un decennio, e i floppy disk sono stati inventati molto dopo la carta comune! Il rischio concreto di perdere decenni di informazioni per colpa dell’obsolescenza verso cui sistematicamente tendono hardware e software nel corso del tempo è la ragione per cui, oltre ad altre strategie, si spendono tempo e risorse per sviluppare emulatori. L’interesse principale è squisitamente scientifico e tecnico, sebbene possano insorgere rari e specifici casi d’interesse commerciale, ad esempio l’emulazione di un software, driver per la periferica incluso, per la lettura di vecchi nastri magnetici contenenti dati sensibili, spesso segreti, di una banca o di un centro di ricerca.
I vantaggi degli emulatori sono da ricercare nella fedeltà quasi massima del comportamento e nel look-and-feel del sistema emulato (a patto che lo si conosca per filo e per segno, se ne parlerà dopo), nel minor costo di gestione e sviluppo rispetto ad altre soluzioni per la preservazione digitale come la migrazione, e nella possibilità di poter eseguire software specifico di un dato sistema su vari sistemi differenti. Inoltre, tranne per i rari scopi prettamente commerciali citati poco fa, gli emulatori vengono sviluppati e rilasciati sotto licenza GNU GPL e open source, affinché chiunque possa collaborare allo sviluppo degli stessi. Il celeberrimo esempio di emulatore nato con il fine di preservazione digitale, che cerca di mantenere quanto più fedelmente possibile il comportamento delle macchine, open source e con sviluppo distribuito su tutto il globo è MAME, l’emulatore multi macchina dei vecchi videogiochi arcade.
Gli svantaggi invece sono da ricercare in una richiesta di risorse hardware sempre maggiore man mano che il sistema da emulare diviene più complesso (si spiegherà dopo il perché), nonché in tutte quelle problematiche legali sull’utilizzo delle proprietà intellettuali detenute dagli sviluppatori e distributori del software emulato, che non sono d’interesse per quest’articolo.

3. Perché è possibile emulare?
Bella domanda: in effetti, per chi non ci capisce molto di informatica può sembrare artificioso o contorto forzare una macchina ad eseguire software che non è suo, oppure può risultare quasi magico ad esempio poter giocare i propri videogames preferiti d’infanzia sul proprio smartphone o PC. Ma di contorto o di magico non c’è nulla: il motivo per cui è possibile, sotto opportune ipotesi, emulare una macchina in un’altra è la cosiddetta tesi di Church-Turing, la congettura su cui poggia tutta la teoria della computazione.

Nel 1936, Alonzo Church ed Alan Turing giunsero, indipendentemente l’uno dall’altro, alla risposta del cosiddetto “problema della decisione” di David Hilbert. Senza addentrarci nel ginepraio dei formalismi matematici, entrambi dimostrarono come non sia possibile poter trovare una soluzione da eseguire meccanicamente (ovvero ciò che oggi viene comunemente chiamato algoritmo) a ogni problema descrivibile attraverso un linguaggio formale, ma solo a quelli effettivamente calcolabili, anche dall’uomo con carta e penna, con risorse di memoria e di tempo teoricamente infinite.

Ma che centra questo con gli emulatori? È presto detto: il formalismo utilizzato da Turing per la risoluzione del problema della decisione è una macchina ideale capace di leggere e scrivere dati su memoria teoricamente infinita e manipolarli per risolvere problemi descritti in un determinato linguaggio di simboli noti alla macchina e che oggi è conosciuta con il suo nome. La macchina di Turing permette di poter definire l’effettiva risolubilità (o, per meglio dire, computabilità) di un problema matematicamente descrivibile attraverso una funzione f : N → N, o sottoinsiemi di N, attraverso un numero finito di passi (descrivibili attraverso lettura, scrittura o spostamento della testina sulla memoria) che essa compie per arrivare alla soluzione. Non tutte quelle funzioni però sono computabili, solo una loro parte: la tesi di Church-Turing appunto afferma che ogni problema risolvibile attraverso un algoritmo espresso in un qualsiasi linguaggio è anche risolubile da una macchina di Turing. Per quanto possano svilupparsi le tecnologie dell’uomo, non è possibile, né lo sarà mai, progettare un calcolatore in grado di risolvere un problema che una macchina di Turing non sia capace di risolvere.
Tra le macchine di Turing possibili si differenziano inoltre quelle universali, cioè capaci di risolvere qualsiasi problema risolvibile da una generica macchina di Turing M. Una macchina di Turing, per essere definita universale (o in breve UTM) deve avere in ingresso la descrizione di M secondo il proprio linguaggio, più un qualsiasi input specifico scelto tra quelli che M può accettare. Ecco la risposta all’uovo di Colombo: siccome ogni calcolatore è associabile, con ovvie limitazioni spaziali e temporali (le memorie infinite purtroppo non sono state ancora inventate!), a una UTM, poiché capace di risolvere un gran numero di problemi computabili, secondo la teoria di Turing un emulatore di un altro calcolatore altro non è che la descrizione di una generica macchina di Turing M, associabile anch’essa a un calcolatore reale, ma più limitato rispetto a quello emulante, mentre il software da emulare ne è l’input specifico.
4. Come viene creato un emulatore?
La tesi di Church-Turing ci assicura che è possibile emulare qualsiasi sistema in un altro, in teoria. In pratica non è affatto così: è comunemente noto il fatto che si possano emulare solo macchine più vecchie e meno performanti rispetto alla macchina ospite, inoltre più il sistema da emulare si complica strutturalmente più l’emulazione può presentare malfunzionamenti oppure diventare completamente inusabile. Il motivo di ciò è nella natura intrinseca dell’emulazione, descritta come sopra: l’hardware della macchina emulata è tutto “trasferito” in un software che deve replicarne il funzionamento quanto più fedelmente possibile. Ciò vuol dire che ogni componente fisico della macchina (CPU, memoria, dispositivi di input/output, chip video ed audio, etc.) deve essere “trascritto” in codice, ed è intuitivo pensare che un maggiore complessità, in numero e in tecnologia, del sistema da emulare implica maggiore corpulenza di codice, librerie, oggetti ed eseguibili nonché maggiore richieste di potenza di calcolo e di memoria. Ciò introduce le due forti problematiche tipiche della creazione di un emulatore: la conoscenza della macchina da emulare e le performance dell’emulatore stesso.
Per raggiungere la piena conoscenza della macchina sono necessari tempo e capacità degli sviluppatori, ma soprattutto ogni informazione reperibile sul sistema: manuali, documentazioni, schemi elettrici, magari l’hardware vero e proprio. Finché si tratta di sistemi che hanno avuto un successo commerciale e con una nutrita schiera di appassionati, come ad esempio gli home computer degli anni ’80 quali lo ZX Spectrum o il Commodore 64 oppure le console storiche Nintendo e SEGA, reperire tali informazioni non è difficile; la situazione si complica notevolmente quando bisogna trattare sistemi poco noti o di scarso successo commerciale, o ancora peggio hardware specifici o non commercializzati come le schede madri di vecchi videogiochi da sala o di terminali di servizio.
In tali casi reperire documentazioni è estremamente complicato, se non di fatto impossibile, e quindi l’unica soluzione praticabile è la cosiddetta ingegneria inversa, ovvero l’insieme di tutte le procedure analitiche del sistema da emulare finalizzate alla scoperta del suo effettivo funzionamento: decompilazione del software posseduto per la macchina da emulare, studio del codice sorgente di quest’ultimo se esso è disponibile, studio qualitativo dell’hardware e del software mentre è in funzione, etc. L’ingegneria inversa però solitamente porta a risultati di compromesso, spesso dipendenti dall’intuito e dall’esperienza di chi la effettua, e che possono portare a prodotti finali incompleti, senza ad esempio funzionalità del sistema che possono essere sfuggite agli analisti; qualche volta invece si può raggiungere risultati anche superiori a quelle che si avrebbero con la documentazione a disposizione, come ad esempio scovare bug nel sistema mai segnalati e che possono essere corretti, oppure scoprire caratteristiche nascoste non documentate da sfruttare per lo sviluppo dell’emulatore.
Per quanto concerne le performance invece, esse dipendono principalmente dall’effettiva programmazione dell’emulatore stesso, successiva allo studio del sistema da emulare. L’utente finale bada quasi esclusivamente al tempo d’esecuzione dell’emulatore: se l’emulatore non “gira” velocemente circa quanto l’hardware del sistema emulato originale, l’emulazione stessa risulta difficoltosa per via dell’eccessiva latenza tra il comando e l’azione, che possono generare interrupt di time-out. Anche i sistemi più semplici al loro interno hanno un sistema di temporizzazione per far sì che il sistema stesso non stagni in un perenne stato d’attesa di un input dell’utente o di un dato specifico, terminando il lavoro che stava compiendo ed eseguendo il successivo; questo vuol dire che se l’emulazione è farraginosa, intercorre troppo tempo per l’esecuzione di un certo task e ciò compromette anche l’effettivo funzionamento di tutto l’emulatore. Nell’ambito dell’emulazione dei videogiochi tale problematica si riscontra soprattutto sul calcolo grafico e sul sonoro, che se troppo lenti generano quell’annoso effetto “a scatti”, noto in gergo come stuttering (in inglese to stutter vuol dire balbettare), dovuto ad una frequenza d’aggiornamento dei fotogrammi a schermo incostante. Quando il carico di lavoro grafico per il sistema ospite è elevato, non viene generato un nuovo fotogramma in tempo utile e viene riproposto quello vecchio, conferendo a schermo un’immagine non fluida; lo stesso vale per l’audio, con le tracce di sottofondo o gli effetti quali spari o esplosioni notevolmente rallentati.
Questa problematica ha portato da qualche anno a una nuova politica sullo sviluppo degli emulatori, che mira a distribuire il carico di lavoro tra i vari co-processori in caso di sistema emulante multiprocessore o multicore (ormai lo standard commerciale) o a sfruttare maggiormente la potenza di calcolo delle GPU. Tale tipo di emulazione viene detta ad alto livello e punta più all’ottimizzazione dell’utilizzo delle risorse a discapito della fedeltà d’emulazione.
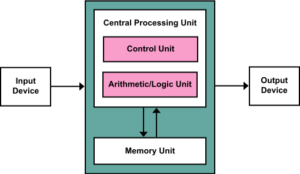
5. Come è composto un emulatore?
Seguendo la scolastica architettura di von Neumann, un calcolatore è composto da un’unità logica di calcolo chiamata CPU (Control Processing Unit), un’unità di memoria centrale e un insieme di periferiche di input e di output, tutte collegate tra loro attraverso un insieme di bus. Siccome un emulatore è la “traduzione” in software di un hardware di un dato sistema, un emulatore si divide in moduli che corrispondono all’incirca alla controparte fisica dei sottosistemi descritti dal modello di von Neumann: un modulo che emula la CPU centrale con ulteriori sottomoduli che emulano eventuali altre unità di calcolo secondarie come chip video o controllori d’accesso alla memoria di massa, un modulo che emula la memoria centrale e una serie di moduli e librerie che emulano i vari dispositivi di input (tastiere, puntatori come mouse o trackball, joystick e pulsantiera nel caso di videogiochi, etc.) e di output (memorie di massa, schermo, etc.). I bus di solito non vengono emulati esplicitamente, sostituiti dalle più semplici da implementare comunicazioni dirette tra i vari moduli.
L’emulatore della CPU è intuitivamente la parte più complessa dell’intero emulatore. Nella maggioranza dei casi esso è un interprete: in ambito informatico, un interprete è un programma che riesce a eseguire altri programmi senza bisogno di compilarne il codice sorgente, ma come suggerisce il nome “traducendo” di volta in volta le righe di codice in linguaggio macchina per poter così essere eseguite. Nello specifico degli emulatori, l’interprete della CPU del sistema emulato traduce il codice del programma emulato in una serie di istruzioni comprensibili alla macchina emulante e semanticamente equivalenti. Fortuna vuole che però i microprocessori più utilizzati ai tempi per quasi tutti i sistemi fossero sempre gli stessi: lo Zilog Z80 a 8 bit, il Motorola 68000 a 16 o 32 bit, il Rockwell 6502 a 8 bit o la famiglia Intel x86 a 16 bit. Questo ha permesso lo sviluppo di emulatori CPU “preconfezionati” che semplificano non poco il lavoro dei programmatori. Un procedimento simile si utilizza anche per i vari processori secondari, come i chip video o audio, indipendentemente che fossero o presenti fisicamente sulla scheda madre della macchina, su schede d’espansione o sulle memorie a cartuccia, come ad esempio il chip Super FX del Super Nintendo usato per la primitiva grafica 3D di Star Fox, con la differenza che i moduli di questi chip supplementari vengono utilizzati dall’emulatore solo quando ne ha effettivamente bisogno.
L’emulazione della memoria è quasi completamente incentrata sull’implementazione del software che replica l’unità di gestione della memoria (in inglese memory management unit o in breve MMU), ovvero quel componente hardware che fa da “vigile urbano” per l’accesso alle locazioni di memoria e da traduttore degli indirizzi di memoria logici e quelli fisici. Brevemente, per scopi di efficienza e di riutilizzo della memoria centrale, a ogni programma vengono assegnate porzioni di memoria non contigue fisicamente (la si pensi come una tabella le cui righe, lunghe un certo numero di bit – ma sempre una potenza di due – vengono definite parole), ma che lo stesso programma vede come tali: compito della MMU è quello di tenere traccia delle correlazioni tra i vari indirizzi logici del programma e quelli effettivi dei banchi di memoria fisici. Vien da sé pensare il fatto che una MMU altro non è che un piccolo processore, anch’esso da replicare come visto per la CPU centrale del sistema emulato. Infine l’effettiva memoria, indipendentemente che fosse la ROM in cui venivano contenuti il firmware e tutto il software necessario per il funzionamento del sistema o la RAM utilizzata per i programmi utente, quasi sempre viene semplicemente implementata nell’emulatore come spazio preallocato nella RAM della macchina ospite. Siccome la macchina ospite non viene utilizzata esclusivamente per l’emulazione, è banale dire che un’emulazione è efficiente se la RAM della macchina ospite è molto più capiente di tutta la memoria che il sistema emulato ha a disposizione.
Per l’emulazione dei dispositivi di input/output a questo livello di dettaglio non c’è molto da dire: essa è quasi esclusivamente effettuata da funzioni che si interpongono tra le periferiche reali e il software emulato. Per la particolare eleganza sono però da ricordare i moduli di particolari dispositivi per l’emulazione di videogiochi, quali i sistemi di puntamento ottici (le cosiddette light-gun) oppure gli schermi vettoriali dei vecchi videogiochi da sala come Asteroids.

6. Come si recupera il software originale?
Il recupero del software per la macchina da emulare non ha una procedura fissa e dipende fortemente dalla tecnologia di memoria di massa utilizzata: nastri magnetici, floppy disk di vario taglio, memorie a transistor, dischi ottici, etc. Se si ha a disposizione il supporto fisico e la periferica relativa per accedervi, la procedura più utilizzata è quella dell’hex dumping: i dati vengono recuperati come una grezza sequenza di byte e ciascun byte viene rappresentato come un numero esadecimale a due cifre. Da questa rappresentazione è possibile controllare sia l’integrità dei dati attraverso funzioni di checksum come una semplice somma modulo 256 oppure metodi più sofisticati come il CRC e l’effettivo contenuto degli stessi attraverso una traduzione in caratteri ASCII degli esadecimali. Quest’ultima serve anche per verificare se i dati ricavati dal dumping sono cifrati per ragioni di protezione anti pirateria, e quindi per poterli utilizzare diventa necessario effettuare procedure di crittoanalisi.

Se è possibile recuperare i dati desecretati, oppure più semplicemente essi sono già in chiaro, si procede alla creazione dei file immagine, comunemente chiamati file ROM, con riferimento alle memorie a transistori a sola lettura (anche se poi il supporto è di diversa tecnologia), attraverso strumenti dedicati e che poi vengono utilizzati per testare l’emulatore. Anche durante questa procedura si possono incontrare difficoltà dovute a sistemi anti pirateria, ma sui contatti fisici anziché sui dati: negli anni ’80 ad esempio era usuale rivestire le schede dei videogiochi da bar con uno strato di resina epossidica, che rendeva molto difficoltosa l’estrazione dei dati senza rischiare di distruggere i chip. Oggi è molto più semplice rimuovere le resine, sebbene resti una procedura delicata. Per quanto riguarda i dischi ottici come CD-ROM e DVD-ROM invece i file immagine sono composti dai contenuti dalle varie tracce e vengono comunemente chiamati file ISO, in riferimento allo standard ISO 9660 del file system per CD-ROM, anche se l’effettivo file system è un altro, come ad esempio l’UDF standard de facto per i DVD.

[/restrict]