Automazione
“Will robots take my job?” è un sito che predice la probabilità di essere rimpiazzati nel proprio mestiere da un computer. In realtà il discorso della perdita di lavoro per colpa dei progressi tecnologici non è sicuramente nuovo. Già durante la prima rivoluzione industriale aleggiava una grande preoccupazione per questo problema. Problema che poi è stato posto ricorsivamente una volta per decennio. L’avvento dei computer, come si può immaginare, generò abbastanza scalpore. Eppure il caos promesso è stato rimandato ogni volta. È dunque possibile che anche questa volta sia tutto un abbaglio, che ci ritroveremo tra dieci anni a chiederci se i robot non stiano per rubarci il lavoro?
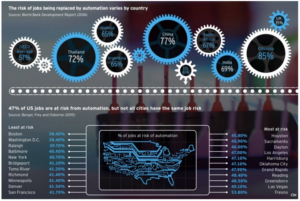
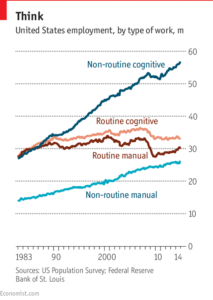
La risposta è: forse si, ma il rischio che ciò succeda diventa di giorno in giorno più tangibile. In primis, è certamente vero che dalla prima rivoluzione industriale i robot e le macchine abbiano rimpiazzato il lavoro umano in molti ambiti. Ciò non è però stato un problema: i cambi di paradigma hanno fatto sì che la disponibilità di forza lavoro fosse reimpiegata in nuove mansioni. Ciò che è preoccupante è il fatto che, ad ogni avanzamento tecnologico, gli impieghi creati richiedano un’istruzione e una preparazione migliori di prima. All’equazione degli avanzamenti tecnologici, che pur aumentando il livello di automazione hanno visto i mestieri spostarsi ad altri ambiti, c’è da aggiungere però un nuovo termine: i mestieri ripetitivi diventano sempre più obsoleti con ogni giorno che passa.
E questo non va ad inficiare solamente i lavori meno qualificati: anche un lavoro come la diagnosi di tumori è a rischio automazione. In una sfida tra un computer e tre radiologi, il computer ha fatto diagnosi del 50% più accurate e non ha avuto falsi positivi, a differenza dei colleghi umani, con una percentuale del 7%. Cosa sta cambiando?
Machine learning
La risposta consiste in due parole: machine learning. Il machine learning è una tecnica che fa più o meno quello che dice il nome: fa imparare le macchine. La tecnica è la soluzione ad un problema recente: data un’enorme mole di dati e una serie di caratteristiche da studiare è possibile far in modo che il computer abbia dei criteri di classificazione per poter saper cosa fare quando riceve un nuovo dato. Questo è quello che si chiama supervised learning. Vi sono altri metodi, come ad esempio l’unsupervised learning e il reinforced learning, ma la loro discussione esce da quest’ambito. Quel che conta è che ciò apra la porta a macchine che riescono a imparare. Questo, appunto, va ad eliminare i mestieri ripetitivi, anche perché in questi casi la macchina è in grado di fare quello che riesce a fare una persona ma molto più velocemente, eliminando l’errore umano.
Questo cambio di paradigma impone di riformulare il metodo educativo: non bisogna più formare individui altamente preparati a eseguire un numero ristretto di mansioni, bensì individui flessibili e in grado di continuare ad imparare nel resto della propria carriera, portandosi dietro e facendo tesoro delle conoscenze precedenti. Una risposta a questo problema sono i cosiddetti MOOCs (Massive Open Online Courses): corsi monotematici online fatti da personalità di spicco nell’ambito in questione, con un esame alla fine, in cambio di un certificato. Ironicamente, un gran numero di questi corsi è volto appunto all’alfabetizzazione nel campo del machine learning e del data crunching, ovvero la “digestione” dei dati al fine di ricavare informazioni utili. Del resto, il modo migliore per non perdere il lavoro per colpa dell’intelligenza artificiale è proprio lavorare all’intelligenza artificiale.
L’idea è proprio quella di fornire corsi che si possano seguire in poco tempo, senza dover necessariamente mettere in pausa il proprio impiego per lunghi periodi per ottenere una laurea o un master, dando la possibilità a un individuo di continuare ad imparare nuovi concetti nel corso della propria carriera. Possibilità che fungerebbe da vaccino nella corsa per non essere sostituiti da una macchina. Oltre all’educazione, tema ricorrente e al centro di scottanti dibattiti politici, sorge il problema: cosa succede a chi rimane indietro? Una domanda certamente da porsi, perché è inevitabile che saranno in molti coloro che si sentiranno abbandonati. Questo è un problema che va ad accrescere le disuguaglianze: le aziende ad alto contenuto tecnologico impiegano molte meno persone e molto più formate, requisiti che vanno ad alzare la probabilità che il gap tra varie classi sociali si allarghi progressivamente.
Basti pensare al fatto che Instagram impiegava solo 13 dipendenti, quando è stata comprata per tre miliardi di dollari da Facebook, quasi in contemporanea con la bancarotta di Kodak, che impiegava invece 145.000 dipendenti. C’è chi ha proposto come soluzione a questo problema il reddito di cittadinanza: la proposta fu inclusa nell’infelice campagna del candidato del Parti Socialiste alle elezioni presidenziali francesi, Benoit Hamon. Nel frattempo l’idea sta venendo sperimentata in vari paesi come Finlandia e Olanda. Il problema dovuto ai computer che apprendono da enormi moli di dati non si ferma però qua.
Data crunching e social networks
Un sistema noto per la sua capacità di generare un’enorme mole di dati è quello dei social network. Dati contenenti la vita quotidiana di ognuno di noi, assieme a opinioni, fede, colori politici e via dicendo. Chi possiede i social network siede, consapevolmente, su una miniera d’oro. Miniera che ci consente di usufruire gratuitamente del servizio. Supponiamo ora che le Facebook Reaction siano un metodo per usare il precedentemente citato supervised learning, puntato sia a predire qual è la reazione dominante per un avvenimento sia per predire cosa ne penserà un determinato individuo. È un gioco che si può fare anche da soli: sapendo da chi è stato condiviso un post e qual è il suo pubblico, generalmente è facile predire la reazione dominante. A questo punto, la gestione del social network possiede due informazioni preziosissime:
- Linee guida per far in modo che un contenuto venga più o meno apprezzato, includendo come mettere un informazione per farla passare nel modo migliore in gruppi sociali diversi;
- La possibilità di prevedere l’opinione dominante su elementi di un’eventuale campagna elettorale.
A ciò si aggiunge l’ovvio risvolto pubblicitario della questione, tramite la creazione di pubblicità su misura per ognuno. Senza considerare l’enorme potere derivante dalla gestione dell’algoritmo che dà visibilità alle notizie sui vari news feed. Il potere di oscurare o al contrario puntare i riflettori su notizie differenti è qualcosa di assurdamente rilevante, in cui l’algoritmo diventa una vera e propria divinità nel luogo astratto che è il social network. Di riflesso, cambia il modo di fare informazione dei vari media, come discusso per il caso di YouTube dallo youtuber Veritasium.
I risvolti politici sono evidenti, e lo diventano ancora di più alla luce della possibilità che Mark Zuckerberg si candidi alle presidenziali statunitensi del 2020 o del 2024. Possibilità per ora smentita, ma del resto anche Donald Trump dichiarò che non si sarebbe candidato, e ora i risultati sono sotto gli occhi di tutti. Sorge perciò il problema: è possibile, è giusto che quest’enorme potere in possesso dei detentori di tali informazioni possa essere usato a fini politici? Sopratutto considerando che società come Google, Facebook e Amazon generano introiti paragonabili a piccole nazioni e hanno un potere che potrebbe destabilizzare la politica nazionale.
In conclusione
Ciò che più preoccupa è che siamo sempre più vicini a un’era in cui la portata e la velocità dei cambiamenti apportati della tecnologia alla nostra vita diverranno sempre più grandi. Vi sono molti altri casi illustri, come i primi appelli per rompere il monopolio che Amazon sta sviluppando, oppure la diatriba tra Mark Zuckerberg e Elon Musk riguardo al pericolo potenziale derivato dall’Intelligenza Artificiale evidenziato da molte personalità di spicco in una lettera aperta. Oppure il caso dei chatbot di Facebook, che – malgrado ciò che dicono alcuni articoli – non hanno sviluppato un linguaggio proprio, ma hanno imparato a mentire tra di loro per scambiarsi in modo più efficiente degli oggetti di valore.
Tenendo conto di quanto potere può accumulare chi è sulla cresta dell’onda dell’innovazione tecnico-scientifica, insomma, risulta fondamentale rendersi conto che non ha più senso rivolgere gli sforzi regolatori a riguardo a posteriori. È essenziale che vi sia uno sforzo legislativo volto alla previsione e prevenzione di eventualità tali. Accanto a sforzi nazionali sono auspicabili sforzi internazionali, visto ad esempio il carattere multinazionale dei cosiddetti FAANG, nome creato per raggruppare Facebook, Amazon, Apple, Netflix e Google, oramai diventati veri e propri imperi. Se ciò non succede, c’è il rischio concreto di vedere cambiare totalmente il mondo che conosciamo. E, a quel punto, la responsabilità di sopravvivenza diventa individuale.